Step 3.7 Flash
The new frontier is agent efficiency.
A high-efficiency Flash model for real-world agents.
Key Features
-
Native Multimodal Understanding & Acting
Understands images across the full range — product UIs, documents, charts, and natural scenes — then writes code or calls tools to act on what it sees.
-
Web & Visual Search Enhancement
Web search reaches further — more sources, deeper follow-up. Visual search recognizes what other systems don't — long-tail entities, freshly emerged concepts.
-
Reliable Tool Use & Orchestration
Drives terminals, browsers, Office tools, search, and beyond — staying coherent however long the run gets. Less drift, fewer broken toolcalls, fewer failed runs.
-
Agent Ecosystem Compatibility
Works with mainstream harnesses (Claude Code, KiloCode, Hermes Agent, OpenClaw) and Skills — lower integration cost, less workflow rewiring.
Agentic Coding
Multimodal
General Agent
Gallery
Agentic Coding
Foundation models are shifting from answering questions to taking action, and in the digital world that action takes the form of code. Coding is the substrate of digital agency, the purest form of the plan–execute–observe–iterate loop, and the leading indicator of where a model's broader agentic capability is heading. We invested heavily in this surface for Step 3.7 Flash. Compared to Step 3.5 Flash, it gains +5% on SWE-Bench Pro and 6.1% on Terminal-Bench 2.1.
Step-SWE-Bench
| Step 3.7 Flash | Step 3.5 Flash | |
|---|---|---|
| Hermes Agent | 67.50% | 60.00% |
| OpenClaw | 67.00% | 47.00% |
| Claude Code | 71.50% | 73.00% |
| KiloCode | 67.50% | 59.00% |
| OpenCode | 64.50% | 57.00% |
| RooCode | 64.50% | 43.00% |
In production, coding agents rarely run on a single scaffold. They live inside a heterogeneous stack of harnesses, each with its own prompting conventions, tool schemas, and orchestration patterns — and a model has to perform reliably across all of them to be genuinely useful. Step 3.7 Flash is markedly more balanced across this stack than Step 3.5 Flash, with the per-harness gap narrowing substantially on our in-house Step-SWE-Bench.
To push quality further without giving up Flash-tier efficiency, Step 3.7 Flash supports Advisor Mode. Step 3.7 Flash drives the trajectory end-to-end — calling tools, reading results, and iterating — and consults a larger advisor model only at the few inflection points where its own judgment falls short, such as planning or recovering from repeated failures. This is Step's implementation of the advisor strategy described by Anthropic, where a small executor stays in control and escalates to a frontier advisor only when needed, keeping most of the run at executor cost. With Advisor Mode enabled, Step 3.7 Flash reaches 97% of Claude Opus 4.6's coding performance at roughly one-ninth the per-task cost ($0.19 v.s. $1.76 per task).
Sharpened for Enterprise Tasks
Enterprise work inherently depends on two critical pillars: autonomous task execution in dynamic environments and deep, domain-specific vertical knowledge. Step 3.7 Flash is purpose-built and rigorously optimized across both frontiers to independently drive assignments and ship production-grade deliverables.
The model combines strong agentic execution with precise intent understanding and rich multimodal perception, allowing it to seamlessly bridge the gap between comprehension and action. Users can hand Step 3.7 Flash a complete piece of knowledge work and trust it to independently map out the plan, search across live sources, extract key information, and fluidly orchestrate tools to deliver a ready-to-ship result without intervention. It reads and directly acts on mixed inputs—such as screenshots, complex documents, and dense spreadsheets—parsing visual context and digital assets simultaneously. This long-horizon task execution is validated across diverse environments, where Step 3.7 Flash achieves 49.5% on Toolathlon for multi-tool coordination and 67.1% on ClawEval-1.1 for daily autonomous task execution in realistic environments.
The path from general intelligence to true professional expertise starts with real expert practices. By partnering deeply with domain specialists, we have embedded native industry know-how into the model, validating its capabilities through our own benchmarks in finance, accounting, and data analysis. This expertise extends well beyond specialized domains: Step 3.7 Flash reaches 45.8% on GDPval across 44 occupations, and passes at over 98% across different reasoning difficulty tiers on Tau2-bench Telecom.
Search Wider and Deeper
For a model at the scale of Step 3.7 Flash, the goal is not to pack every piece of world knowledge into its weights, but to make the model better at calling upon that knowledge when needed. We therefore focus its capabilities on search planning, evidence filtering, and information synthesis, turning search from an external add-on into a native part of the reasoning process.
Step 3.7 Flash delivers strong results across search-heavy benchmarks. It scores 47.20% on HLE with Tools, up from 35.68% (text-only) for Step 3.5 Flash, and outperforms Flash models from DeepSeek V4 and Gemini 3.5. It reaches 75.82% on BrowseComp, approaching larger models such as Claude Opus 4.7 and GLM 5.1. On DeepSearchQA, it achieves 92.82% F1 score, comparable to Kimi K2.6, a 1T / 32B-active model. On ResearchRubrics, it scores 71.68%, ahead of GPT 5.5 at 61.50% and close to Claude Opus 4.7 at 73.92%. These results show that Step 3.7 Flash combines Flash-level efficiency with strong deep-retrieval and research capabilities.
 play ▶
play ▶
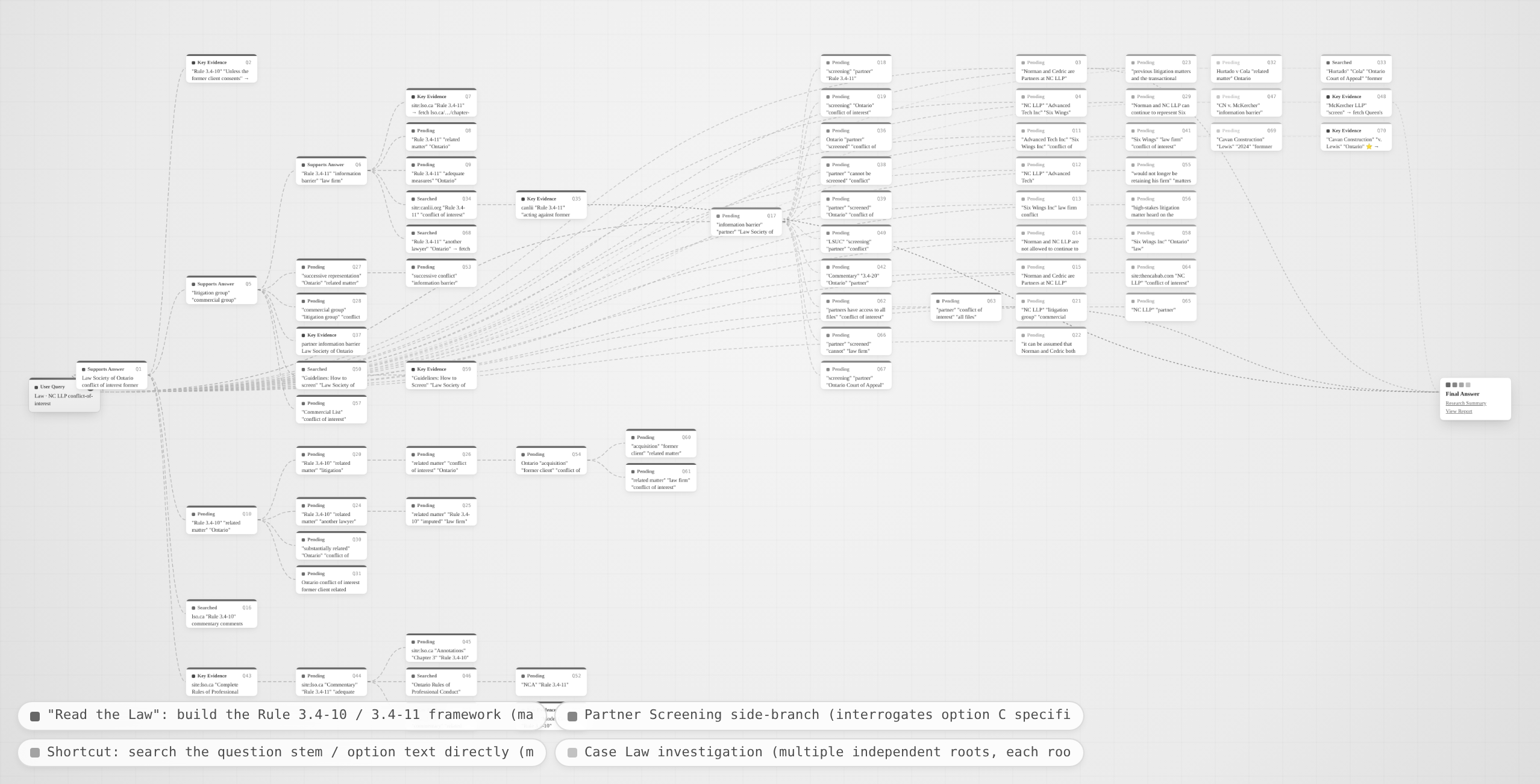
The trajectories further highlight both the breadth and depth of its search behavior. In the Ontario lawyer conflict-of-interest case, it similarly expanded its search around domain-specific concepts, combined evidence from papers, course materials, official rules, and case analyses, and caught the key traps in the questions.
Agents That Can SEE
We establish Step 3.7 Flash as an agentic foundation model with vision input support, shifting perception and recognition from parametric capacity to test-time scaling with visual tools. As the first of these, we strengthen its ability to invoke the Visual Search tool, thereby compensating for the parametric knowledge deficiencies caused by Step 3.7 Flash's limited model size. As shown in the table below, on visual recognition tasks, Step 3.7 Flash with Visual Search achieves performance on par with models five times its size.
Visual Recognition with Visual Search
| Flash Level | Pro Level | |||
|---|---|---|---|---|
| Benchmarks | Step 3.7 Flash | Kimi K2.6 | GLM 5V Turbo | GPT 5.5 |
| SimpleVQA | 79.16% | 78.24%* | 78.20% | 79.11%* |
| WorldVQA | 58.10% | 55.98%* | 47.81%* | 54.58%* |
| BC-VL | 58.96% | 57.12%* | 51.90%* | 65.68%* |
- * denotes a self-tested score.
For a broader set of challenging vision tasks that demand fine-grained perception over high-resolution images or visual reasoning capabilities—such as V*, HR-Bench, and VisualProbe—we grant the model an enriched action space to interact with images, including cropping, zooming in and out, and drawing pixels or bounding boxes. These tools are implemented as a unified code interface, commonly referred to in the field as the Python tool. With Python, Step 3.7 Flash achieves exceptionally strong performance on these benchmarks.
Visual Perception with Python Tool
| Flash Level | Pro Level | |||
|---|---|---|---|---|
| Benchmarks | Step 3.7 Flash | Kimi K2.6 | GLM 5V Turbo | Gemini 3 Flash |
| V* | 95.29% | 96.90% | 89.00% | 96.30% |
| HR-Bench 4K | 89.13% | 91.25%* | 84.62% | 94.50% |
| HR-Bench 8K | 86.34% | 90.13%* | 83.12% | 94.80% |
| VisualProbe | 65.05% | 64.47%* | 53.01% | 69.90% |
- * denotes a self-tested score.
- The GLM results were aligned with official GLM personnel, using crop + search and other tools.
One particularly interesting finding is the emergent ability of compositional generalization across visual and other tools. During testing, Step 3.7 Flash seamlessly combined visual tools with non-visual ones to accomplish complex tasks, despite never having been explicitly guided toward such compositional tool use during training.
Visual Reasoning with Python Tool
Compositional Usage across Visual and Non-visual Tools
Operating graphical user interfaces (GUI) is another foundational visual capability for an agentic model — many real-world tasks live beyond the chatbox and the CLI, and require the agent to see, click, and verify. We extend Step 3.7 Flash with GUI operation, in particular for the Phone-use stack, so that it can complete long-horizon tasks across multiple apps. On the Android Daily benchmark, Step 3.7 Flash achieves a substantial improvement over last year's Step-GUI in stability, robustness, and long-horizon completion, and ahead of other models of larger scale.
Score of Android Daily Benchmark
- * denotes a self-tested score.
- Android Daily: https://arxiv.org/abs/2605.27761
The same compositional pattern we observed across visual tools also surfaces here: in the following case, after writing a piece of frontend code, the model autonomously turned to the GUI to test the page it had just produced — inspecting the rendered output, exercising interactive elements, and iterating on its own code based on what it saw. Again, this code-and-GUI compositional behavior was never explicitly demonstrated or rewarded during training, yet emerges robustly in test-time use.
GUI Operation
Benchmarks
In our benchmark table, we provide a detailed, side-by-side comparison of today's top-performing open-source models. Across a wide range of metrics, Step 3.7 Flash stands out with consistently strong results. Our evaluation focuses on three core dimensions—Reasoning, Coding and Agentic Capability.
| Flash Level | Pro Level | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Benchmarks | Step 3.7 Flash | Step 3.5 Flash | DeepSeek V4 Flash | Gemini 3.5 Flash | DeepSeek V4 Pro | GPT 5.5 | Claude Opus 4.7 | Kimi K2.6 | GLM 5.1 |
| Total Params | 196B + 1.8B (ViT) | 196B | 284B | — | 1.6T | — | — | 1T | 754B |
| Active Params | 11B | 11B | 13B | — | 49B | — | — | 32B | 40B |
| Multi-modal | |||||||||
| General Agent | |||||||||
| HLE w. tool (acc) | 47.2% (text-only 49.7%) | 35.7% | 45.1% | 40.2% | 48.2% | 52.2% | 54.7% | 54.0% | 52.3% |
| BrowseComp (acc) | 75.8% | 69.0% | 73.2% | — | 83.4% | 90.1% | 79.3% | 83.2% | 79.3% |
| deepsearchQA (F1) | 92.8% | 85.5%* | 90.6%* | — | — | 94.0%* | 91.7%* | 92.5% | 91.2%* |
| deepsearchQA (acc) | 81.7% | 73.4% | 79.8%* | — | — | 85.3%* | 82.3%* | 83.0% | 81.3%* |
| ResearchRubrics (score) | 71.7% | 65.3% | 66.2%* | 63.6%* | 68.3%* | 61.5%* | 73.9%* | 63.0%* | 67.9%* |
| Toolathlon | 49.5% | 33.3% | 52.8%* | 56.5% | 56.6%* | 60.2%* | 65.4%* | 54.6%* | 48.1%* |
| Claweval-v1.1 (pass^3) | 67.1% | 43.6% | 57.8% | — | 59.8% | — | — | 62.3% | 62.3% |
| GDPval-Stirrup | 1415.8 (ii 45.8%) | 1055.0 (ii 27.8%) | 1414.0 (ii 44.0%) | 1656.0 (ii 57.8%) | 1554.0 (ii 53.0%) | 1769.0 (ii 63.0%) | 1753.0 (ii 63.0%) | 1481.0 (ii 49.0%) | 1535.0 (ii 52.0%) |
| Coding | |||||||||
| SWE-MTLG | 72.4% | 67.4% | 73.3% | — | 76.2% | — | 80.5% | 76.7% | — |
| SWE-Bench Pro | 56.3% | 51.3% | 55.6%* | 55.1% | 55.4% | 58.6% | 64.3% | 58.6% | 58.4% |
| SWE-Bench Verified | 76.5% | 74.4% | 79.0%* | — | 80.6% | — | 87.6% | 80.2% | — |
| Terminal-Bench 2.1 | 59.6% | 53.4% | 62.0%* | 76.2% | 72.0% | 82.7% | 69.4% | 66.7% | 69.0% |
| Long Context | |||||||||
| AA-LCR (avg@16/acc) | 63.9% | 45.5% | 63.7% | 71.0% | 66.3% | 74.3% | 70.3% | 69.1% | 64.9% |
- "—" indicates the score is not publicly available or not tested. * denotes a self-tested score.
- Step 3.7 Flash, Gemini 3.5 Flash, DeepSeek V4 Flash, DeepSeek V4 Pro and GLM 5.1 are benchmarked on Terminal-Bench 2.1; DeepSeek V4 Flash’s metrics come from our internal testing. Kimi-K2.6, GPT 5.5 and Claude Opus 4.7 rely on official reported results on Terminal-Bench 2.0.
- Android Daily: https://arxiv.org/abs/2605.27761
Availability, Deployment, and Ecosystem
Availability
Step 3.7 Flash is available on the StepFun Open Platform — platform.stepfun.ai (global) and platform.stepfun.com (China), OpenRouter, and NVIDIA NIM. StepFun is also partnering with DeepInfra, Fireworks AI, and Modal to expand availability soon.
Deployment
Step 3.7 Flash supports flexible deployment across cloud, data center, and local environments. For large-scale production and enterprise use cases, Step 3.7 Flash can be deployed on modern data center infrastructure. For local and workstation scenarios, it can also run on high-memory devices such as NVIDIA DGX Station, AMD Ryzen AI Max+ 395-based systems, and Mac Studio / Macbook Pro devices with at least 128GB unified memory.
Ecosystem
Step 3.7 Flash is supported across popular open-source infrastructure for both inference and model development. For inference and serving, developers can use vLLM, SGLang, Hugging Face Transformers, and llama.cpp. For model development & customization workflows, StepFun model support has landed in the NVIDIA Nemo ecosystem, including AutoModel, Megatron Core and Megatron Bridge. Step 3.7 Flash is also available as an NVIDIA NIM inference microservice for on-prem, cloud, or hybrid deployment.